Profiling¶
constfilt includes a profiling suite that measures compile-time cost, runtime
throughput, and numerical accuracy. Results are committed under
docs/profiling/results/ so that it is easy to track regressions and improvements.
Running¶
The Octave accuracy reference must be generated before the first run:
What is measured¶
Compile-time cost¶
Each file under profiling/compile_time/ forces a static constexpr filter
instantiation; the compiler must evaluate all coefficient math at compile time.
Wall time and peak RSS are recorded by the shell.

Compile time grows roughly exponentially with order. All tested orders (up to 12) compile successfully. For Butterworth, Tustin sits between MatchedZ and ZOH at each order. For Elliptic, Tustin compiles faster than MatchedZ at every tested order, and faster than ZOH by a wider margin.
Runtime throughput¶
Benchmarks process 5 million samples and report the best time across 5 repetitions, in nanoseconds per sample.
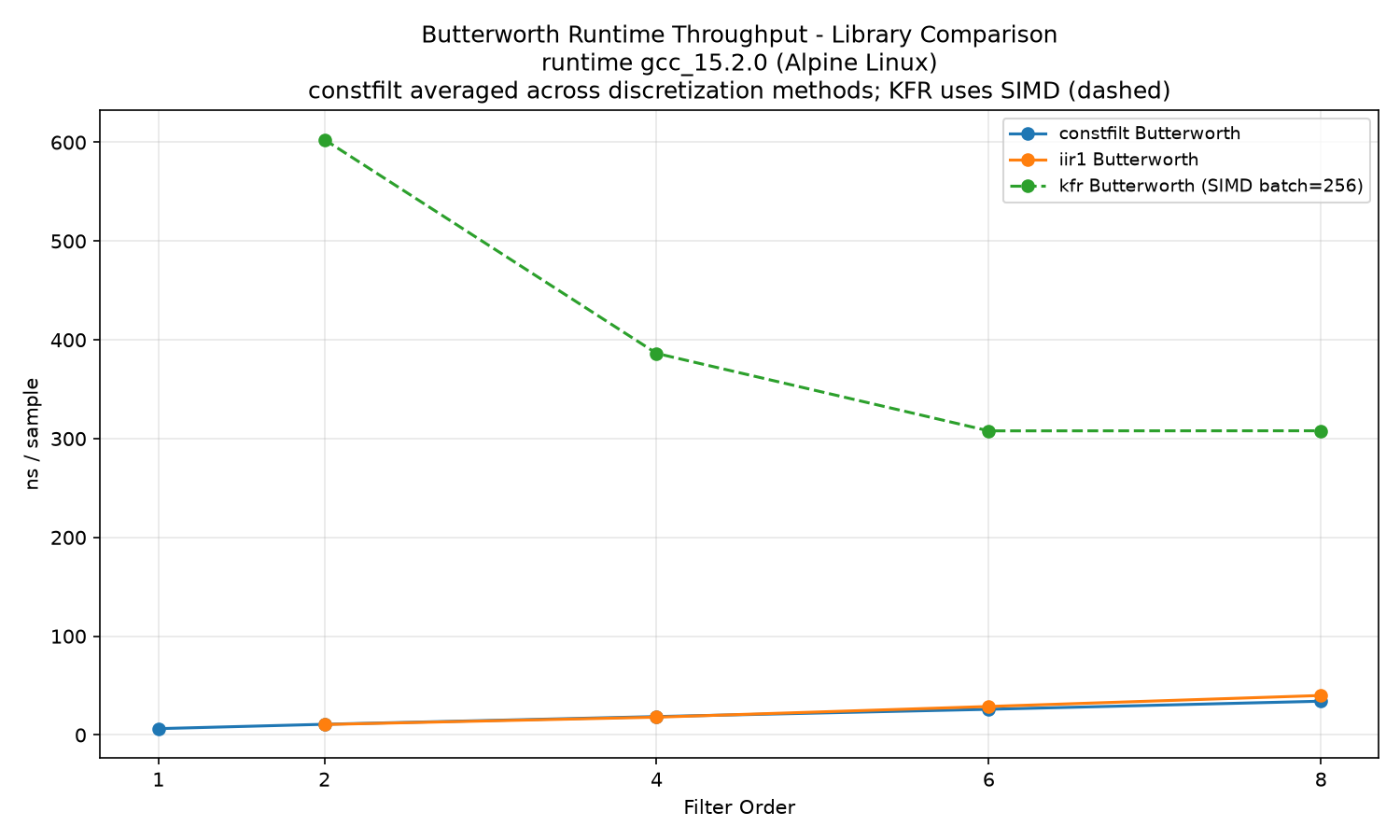
Butterworth library comparison (constfilt averaged across discretization methods):
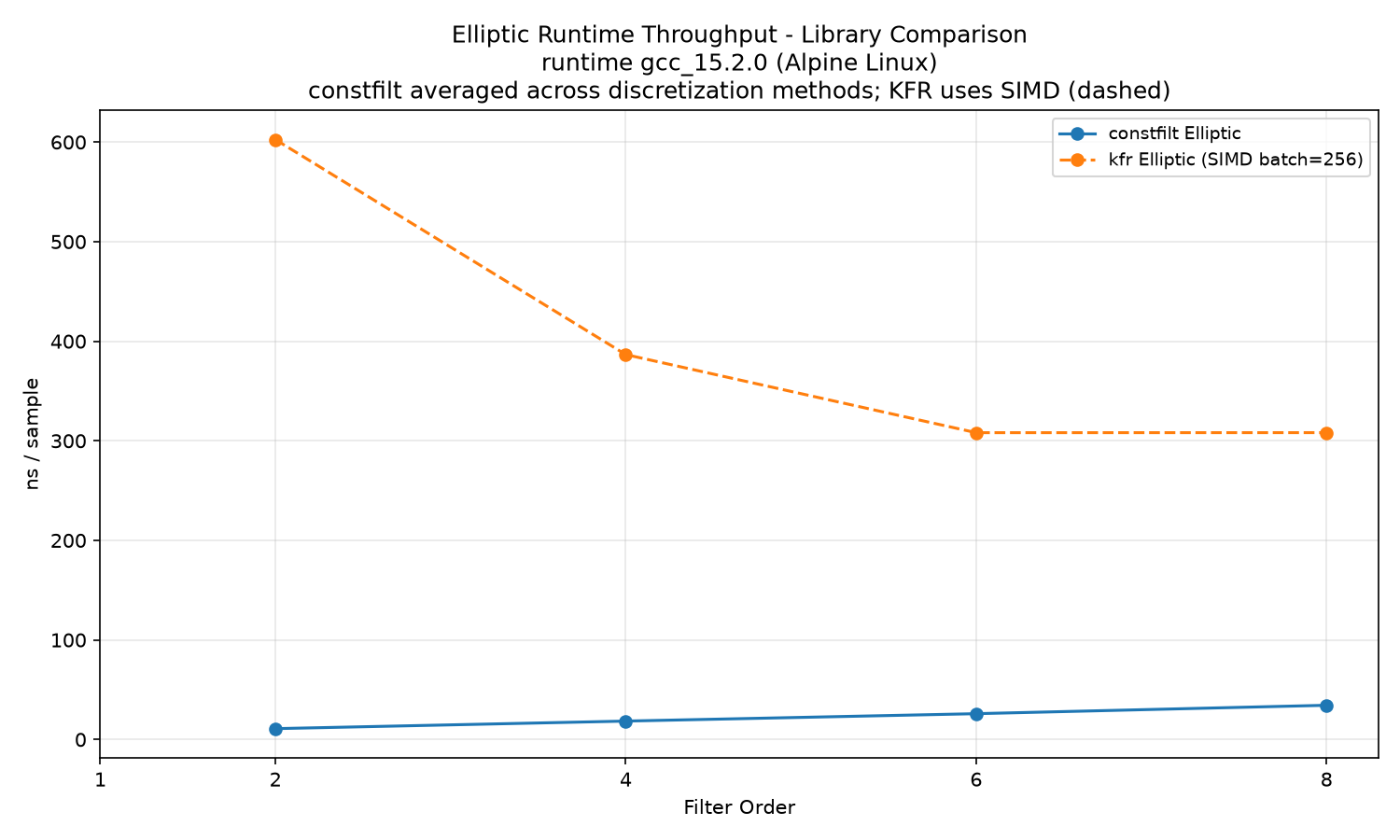
Elliptic library comparison (constfilt averaged across discretization methods):
constfilt all filter types and discretization methods:
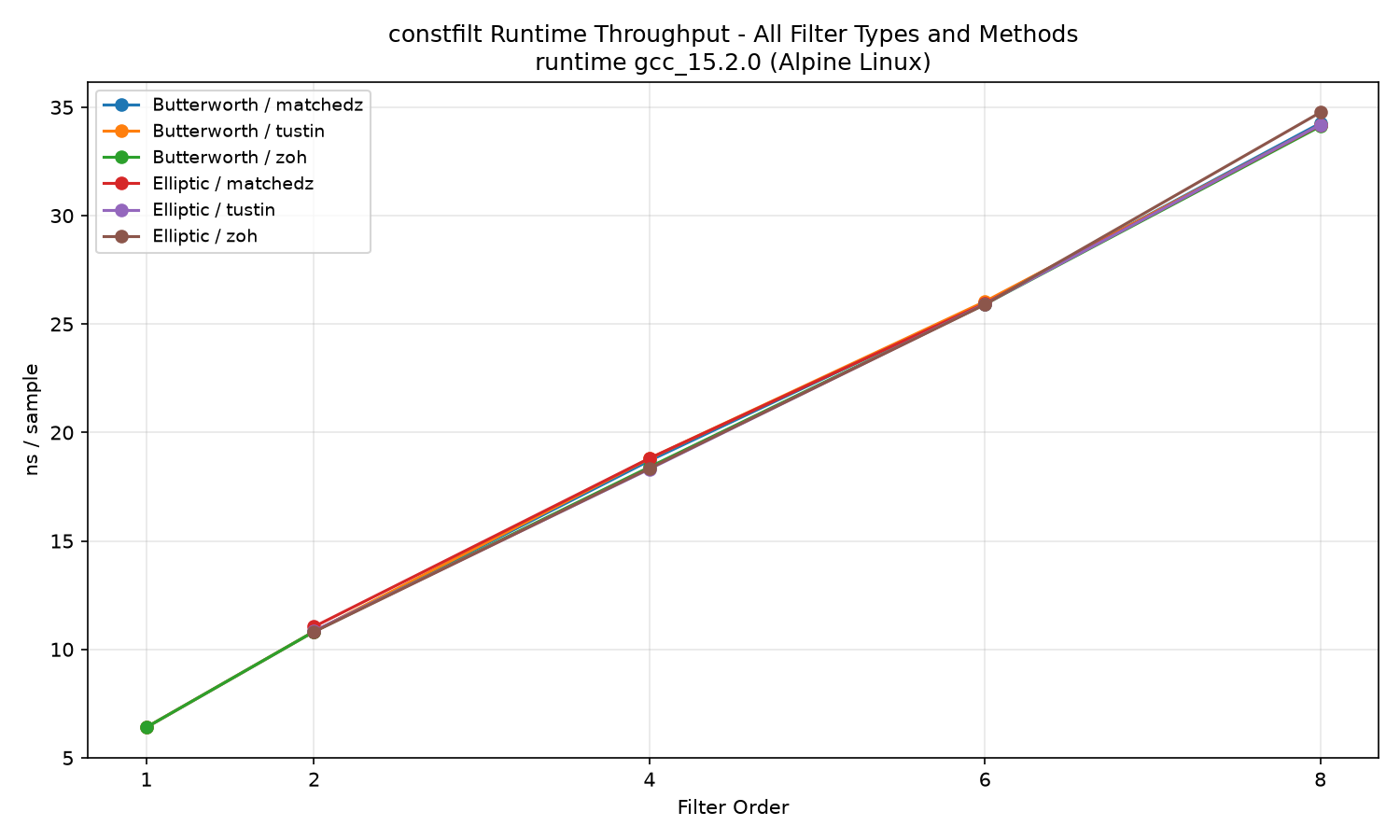
constfilt and iir1 scale roughly linearly with filter order and are within a few nanoseconds of each other. Elliptic throughput matches Butterworth at the same order because both use the same Direct Form II Transposed runtime path. See the Comparison libraries section for notes on the kfr results.
Numerical accuracy¶
Coefficient and step response accuracy are measured against an Octave reference for orders 1 through 12.
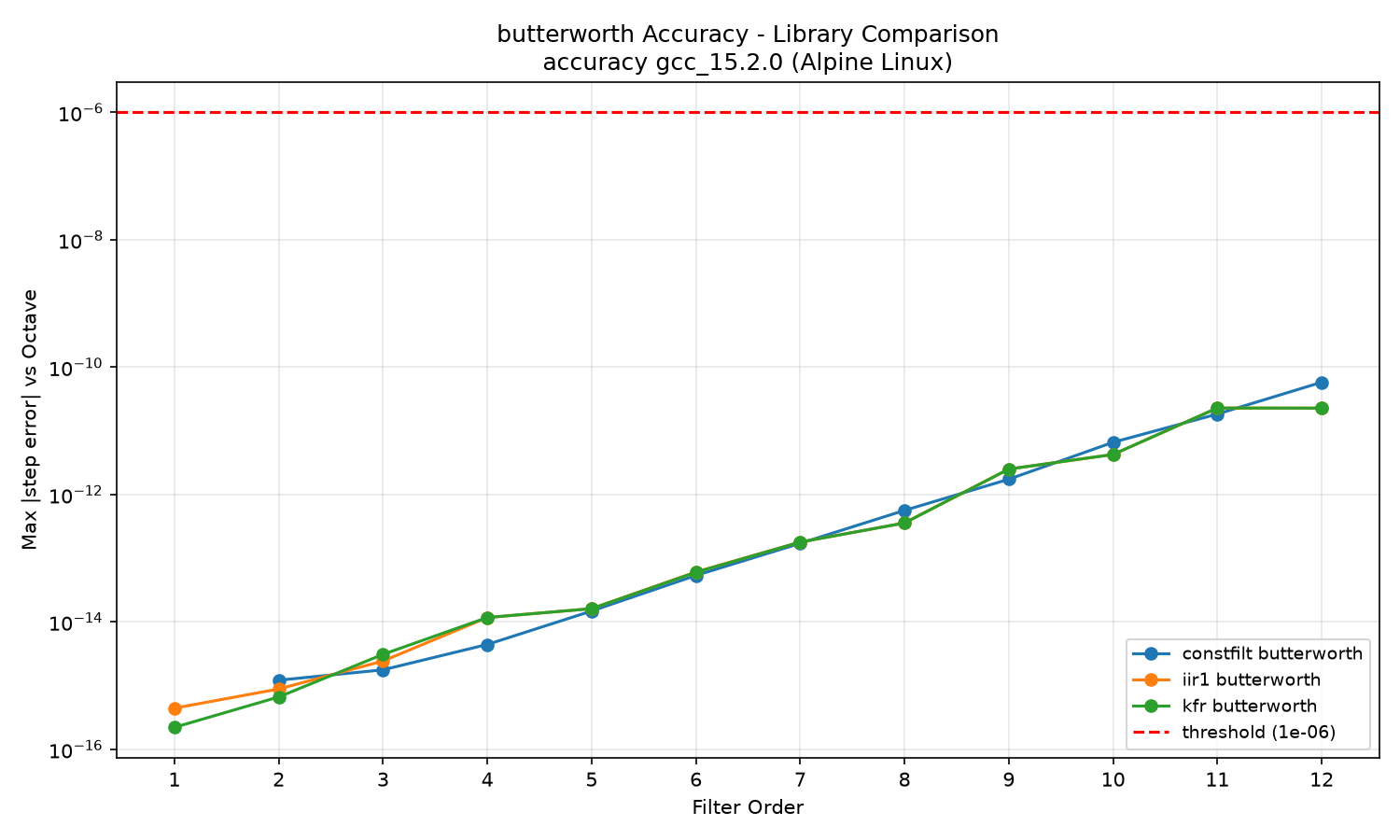
Butterworth library comparison:
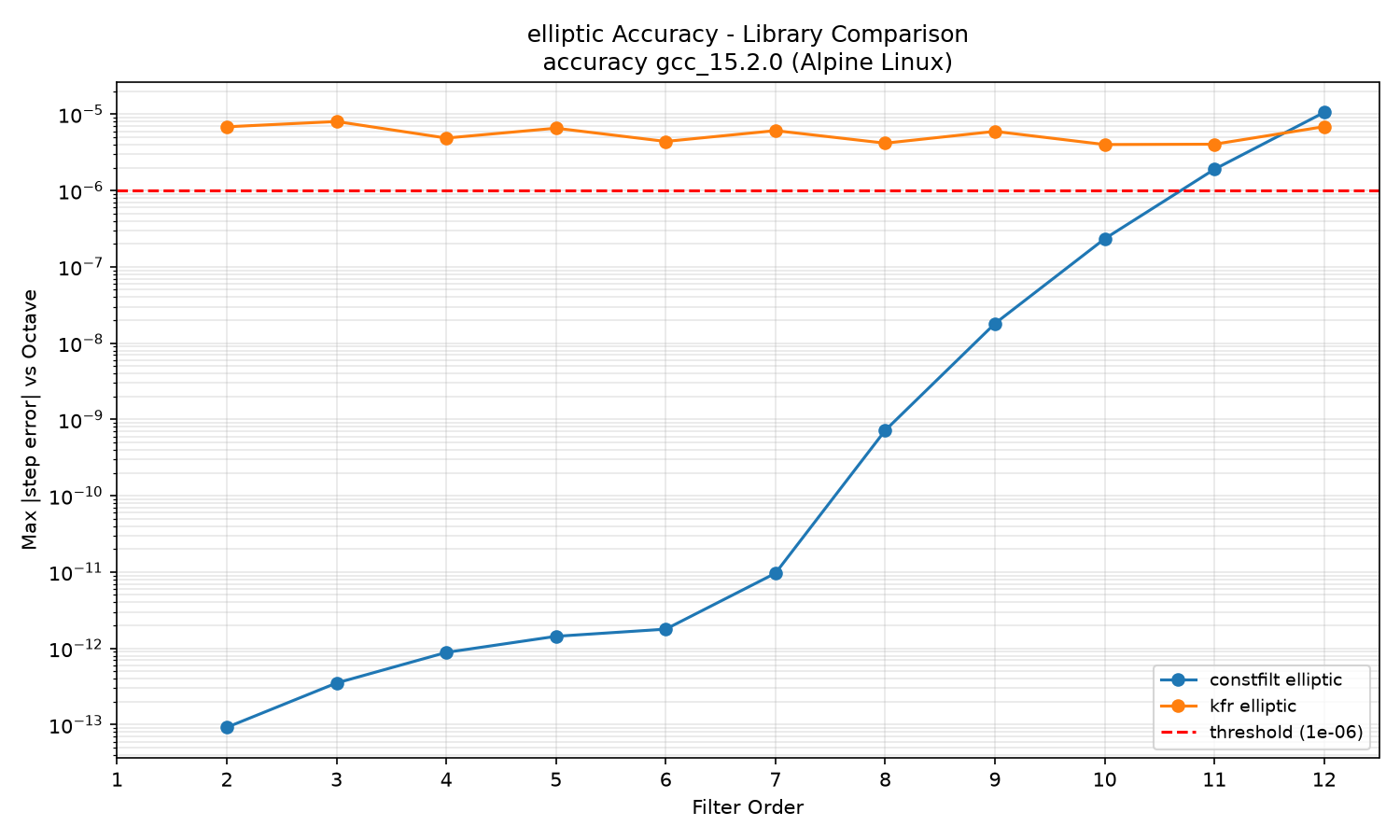
Elliptic library comparison:
constfilt all filter types and discretization methods:
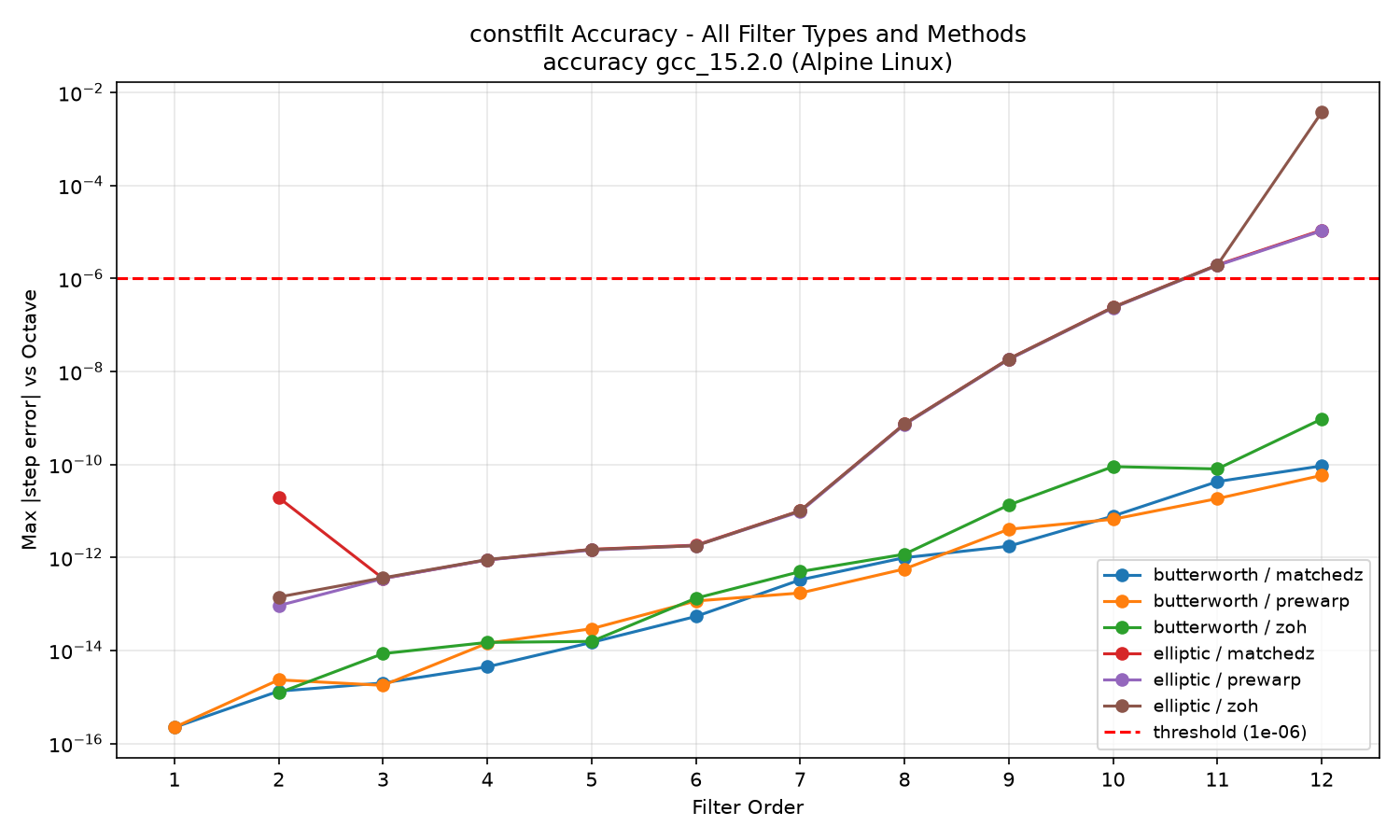
ZOH accuracy degrades sharply above order 8 because the matrix exponential uses eigendecomposition, which loses precision as eigenvalues spread at high orders. MatchedZ and Tustin (prewarped) remain near machine precision through order 12; TustinNW would show a systematic cutoff-frequency offset against this reference because the Octave reference uses the prewarped bilinear transform. kfr's elliptic step responses differ from the Octave reference by roughly 1e-5 to 1e-6 across all tested orders, which I think reflects a different pole placement algorithm rather than a numerical precision problem (issue #41).
Comparison libraries¶
iir1 does runtime coefficient design and Direct Form II Transposed filtering with plain scalar doubles, covering Butterworth only.
KFR is a SIMD-accelerated DSP library. Its
iir_filter<T> is a type-erased convenience class: each apply(dest, src, N)
call heap-allocates a wrapper for the input pointer, substitutes it into a
type-erased expression tree, then dispatches each chunk through two levels of
virtual function pointers. The benchmarks are built without optimization flags,
so none of this inlines and the overhead dominates. At -O2 or -O3 the
compiler very likely (issue #42) collapses the expression chain and the gap with scalar
implementations narrows substantially. The kfr runtime numbers reflect
abstraction cost at zero optimization, not kfr's peak IIR throughput.
Interpreting results¶
Compile-time cost scales with constexpr instantiation depth, not runtime cost. A filter that takes 1 second to compile runs at the same ns/sample as one that compiled in 80 ms.
Runtime numbers are measured without optimization flags, so they reflect per-sample call overhead rather than peak throughput. constfilt and iir1 are built under the same conditions and are meant to be an apples-to-apples comparison.
Accuracy is measured against Octave's Signal Processing Toolbox. constfilt ZOH diverges from the reference above order 8 due to eigendecomposition conditioning; constfilt MatchedZ and Tustin (prewarped) remain accurate through order 12. TustinNW accuracy against this reference would reflect cutoff warping, not numerical precision loss.